
Recognizing text with the Vision framework
Learn how to recognize text using the camera with the Vision framework capabilities in a SwiftUI app.

Apple's Vision framework gives developers maximum control over text and image processing so that they can carry out many computer vision tasks, such as detecting and recognizing text. By embedding it into apps, you can address a multitude of scenarios: scanning documents, receipts, or any text-based content is only a taste of the big potential this framework offers.
In this reference, we will show you how to create a simple app for text recognition using the Vision framework within the SwiftUI scope. More precisely, the AVFoundation framework will help us capture live camera frames, and Vision will go along with it so that it can recognize the text.
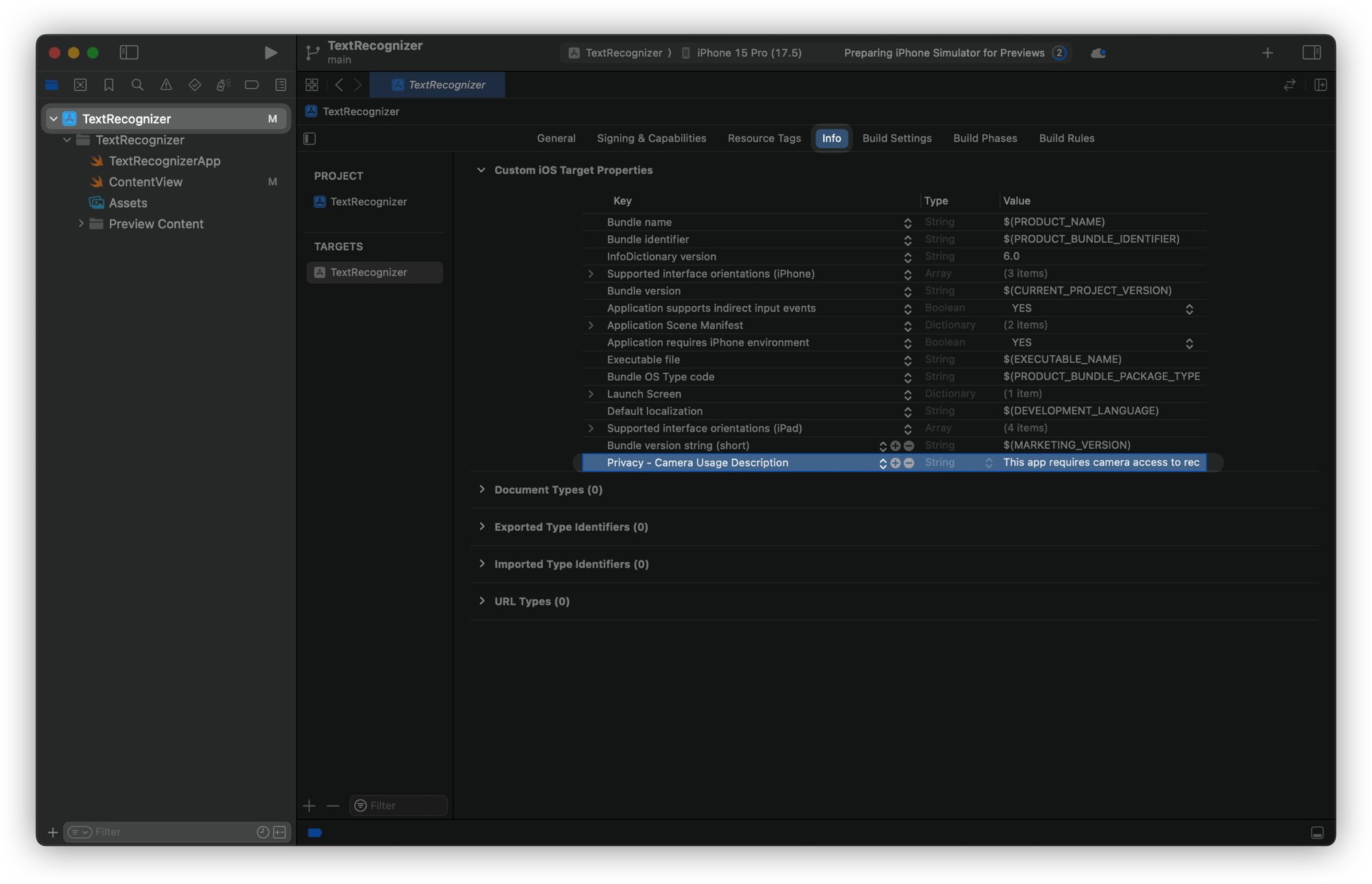
The first thing to do is start a new project in Xcode and set up the App Permissions so that user authorization is necessary for the app to access the user’s camera.
- In the Project Navigator, select your project and then your app target.
- Go to the Info tab.
- Hover over Custom iOS Target Properties and click the + button.
- Add the key
Privacy - Camera Usage Description(NSCameraUsageDescription) with a value explaining why your app needs camera access (e.g., "This app requires camera access to recognize text.").
Navigate to the file called ContentView.swift and add the following code:
import SwiftUI
import AVFoundation
import Vision
// 1. Application main interface
struct ContentView: View {
@State private var recognizedText: String = "Scan for text"
var body: some View {
ZStack(alignment: .bottom) {
ScannerView(recognizedText: $recognizedText)
.edgesIgnoringSafeArea(.all)
Text(recognizedText)
.padding()
.background(.ultraThinMaterial)
.clipShape(RoundedRectangle(cornerRadius: 10))
.padding()
}
}
}
- The
ContentViewis the view where the camera feed comes from and the detected text is outputted on the screen. - The
ScannerView, in particular, is responsible for the text detection, whereas the recognized text appears in theTextview as soon as it is detected.
Now, let's take a look at how to handle the camera feed and the text detection in the ScannerView:
import SwiftUI
import AVFoundation
import Vision
// 1. Application main interface
struct ContentView: View { ... }
// 2. Implementing the view responsible for scanning the data
struct ScannerView: UIViewControllerRepresentable {
@Binding var recognizedText: String
let captureSession = AVCaptureSession()
func makeUIViewController(context: Context) -> UIViewController {
let viewController = UIViewController()
guard let videoCaptureDevice = AVCaptureDevice.default(for: .video),
let videoInput = try? AVCaptureDeviceInput(device: videoCaptureDevice),
captureSession.canAddInput(videoInput) else { return viewController }
captureSession.addInput(videoInput)
let videoOutput = AVCaptureVideoDataOutput()
if captureSession.canAddOutput(videoOutput) {
videoOutput.setSampleBufferDelegate(context.coordinator, queue: DispatchQueue(label: "videoQueue"))
captureSession.addOutput(videoOutput)
}
let previewLayer = AVCaptureVideoPreviewLayer(session: captureSession)
previewLayer.frame = viewController.view.bounds
previewLayer.videoGravity = .resizeAspectFill
viewController.view.layer.addSublayer(previewLayer)
captureSession.startRunning()
return viewController
}
func updateUIViewController(_ uiViewController: UIViewController, context: Context) {}
func makeCoordinator() -> Coordinator {
Coordinator(self)
}
// 3. Implementing the Coordinator class
class Coordinator: NSObject, AVCaptureVideoDataOutputSampleBufferDelegate { }
}
}
ScannerViewconforms to theUIViewControllerRepresentableprotocol.- The
makeUIViewController(context:)function is mainly responsible for the configuration of theAVCaptureSessionwhich is used for video input from the camera. AVCaptureVideoDataOutputtakes the input of each video frame, and theCoordinatoris the delegate who uses the video frames to do the processing of the frames.
Finally, the Coordinator’s actual job is to recognize the text from a given video frame using Vision:
import SwiftUI
import AVFoundation
import Vision
// 1. Application main interface
struct ContentView: View { ... }
// 2. Implementing the view responsible for scanning the data
struct ScannerView: UIViewControllerRepresentable {
...
// 3. Implementing the Coordinator class
class Coordinator: NSObject, AVCaptureVideoDataOutputSampleBufferDelegate {
var parent: ScannerView
init(_ parent: ScannerView) {
self.parent = parent
}
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return }
self.detectText(in: pixelBuffer)
}
func detectText(in pixelBuffer: CVPixelBuffer) {
let request = VNRecognizeTextRequest { (request, error) in
guard let results = request.results as? [VNRecognizedTextObservation],
let recognizedText = results.first?.topCandidates(1).first?.string else { return }
self.parent.recognizedText = recognizedText
// Optionally, stop scanning after first detection
// self.parent.captureSession.stopRunning()
}
request.recognitionLevel = .accurate
let handler = VNImageRequestHandler(cvPixelBuffer: pixelBuffer, orientation: .up, options: [:])
do {
try handler.perform([request])
} catch {
print("Text recognition failed: \(error)")
}
}
}
}
- The
Coordinatorclass is the implementation ofAVCaptureVideoDataOutputSampleBufferDelegateand its task is to handle the video frames that the camera obtains. - Each frame is processed in the
captureOutput(_:didOutput:from:)method to extract aCVPixelBuffer. - The
detectText(in:)method uses Vision’sVNRecognizeTextRequestto analyze the whole pixel buffer and recognize text. As you can see, we adjusted the accuracy and speed of the recognition through therecognitionLevelproperty. Here are some recommendations: (i) If accuracy is paramount, useaccurate(though it takes longer), whereasfastis more suitable for speed-sensitive tasks. (ii) You can specify the detection’s text orientation manually when processing an image buffer. I chose to set it toupwhen initializing theVNImageRequestHandler, but you can choose what best fits your app’s requirements. - If text is recognized, its value is assigned to the
recognizedTextvariable, which is then displayed in theContentView.
The Vision framework's text recognition capabilities allow for extracting and displaying detected text from the camera feed in real-time.
Vision does not only extract and display detected text from the camera feed in real-time, but it can also detect text in different regions of the frame and return bounding boxes for each detected text fragment. This is because it is common for text to be dispersed across multiple regions of a camera feed.
If you want this kind of information, here is how to access it:
for observation in results {
if let recognizedText = observation.topCandidates(1).first {
print("Detected text: \(recognizedText.string)")
print("Bounding Box: \(observation.boundingBox)")
}
}
Moreover, Vision offers confidence ratings for every text segment it detects, enabling you to ignore observations with low confidence for more accurate recognition.
You can filter results based on confidence like this:
if let recognizedText = results.first?.topCandidates(1).first, recognizedText.confidence > 0.8 {
print("High confidence text: \(recognizedText.string)")
}
Logging Error: Failed to initialize logging system. Log messages may be missing. If this issue persists, try setting IDEPreferLogStreaming=YES in the active scheme actions environment variables.
These features can only be tested on a physical device, as the camera won't work on the Simulator or Xcode Preview.
In addition to the method of text recognition shown above, Vision offers several other powerful customizations and variations that can significantly enhance and refine the process.
For instance, once you create an instance of a VNRecognizeTextRequest, you can configure the text recognition process to handle specific languages by setting the request instance’s recognitionLanguages property. This ensures Vision focuses on particular languages, improving accuracy when you know the target text language.
request.recognitionLanguages = ["es-ES", "en-US"] // Spanish and English (US)
Additionally, the possibility of custom-defining character sets by limiting the recognition to certain words, characters, or symbols gives an easier way to extract the text required for your app. For example, if you just need only certain words to be recognized.
request.customWords = ["Create", "with", "Swift"]
Furthermore, if your application requires filtering out noise or very small text, the minimumTextHeight property allows you to focus on larger text, avoiding unnecessary recognition of minor elements:
request.minimumTextHeight = 0.05 // 5% of the image height
And, eventually, the turning off of the language correction also contributes to the acceleration of the process when no corrections are needed:
request.usesLanguageCorrection = false
Vision also offers integration with other tasks. For example, you can combine text recognition with face detection or object recognition by running multiple requests simultaneously:
let textRequest = VNRecognizeTextRequest()
let faceRequest = VNDetectFaceRectanglesRequest()
let handler = VNImageRequestHandler(cvPixelBuffer: pixelBuffer, options: [:])
try? handler.perform([textRequest, faceRequest])
To sum up, the Vision framework is a reliable tool that helps with efficient text recognition in several different contexts. In fact, it offers several customizable recognition settings, multi-language support and the potential for handling real-time data with progressive text recognitions.
You’ve learned how to integrate Vision’s built-in text recognition into your SwiftUI application, but you can use this as a foundation to further build out the text recognition functionality with additional features.
Anyway, text recognition is just one of many powerful features offered by the Vision framework. If you're interested in other features, check these other articles: