
Transcribing audio from live audio using the Speech framework
Learn how to create a SwiftUI application that transcribes audio to text using the Speech framework.

In "Transcribing audio from a file using the Speech framework", we saw how to transcribe speech from an audio file using the Speech supporting framework included in CoreML. This tutorial will focus on implementing a live transcriber feature using the microphone to recognize speech in real-time.
By the end of this tutorial, you will understand how to access an audio buffer using the microphone and then make it available for the Speech recognition framework to process and convert into text.
Step 1 - Define the logic
The first step is creating a new class responsible for accessing the microphone and starting the recognition process.
Start by creating a new file named SpeechRecognizer and importing the AVFoundation and Speech framework. Then we will define all the needed properties.
import Foundation
import AVFoundation
import Speech
@Observable
class SpeechRecognizer {
// 1.
var recognizedText: String = "No speech recognized"
var startedListening: Bool = false
// 2.
var audioEngine: AVAudioEngine!
// 3.
var speechRecognizer: SFSpeechRecognizer!
// 4.
var recognitionRequest: SFSpeechAudioBufferRecognitionRequest!
// 5.
var recognitionTask: SFSpeechRecognitionTask!
}- The
recognizedTextproperty contains the recognized text from the speech input. Initially, it’s set to"No speech recognized"and then will be updated with the actual recognized speech. ThestartedListeningproperty is used to check when the transcription is active. - the
audioEngineproperty is used to handle the audio input from the microphone - the
speechRecognizerproperty manages the recognition process - the
recognitionRequestis a type of request that provides the audio input from theaudioEngineto thespeechRecognizer. - The
recognitionTaskproperty manages the status of the transcription
Step 2 - Enable microphone usage
Now that we have all the necessary property we need to prompt the user to get microphone access. We will do that by defining a new method, setupSpeechRecognition().
@Observable
class SpeechRecognizer {
// Properties declared in the step 1
...
init() {
setupSpeechRecognition()
}
func setupSpeechRecognition() {
// 1.
audioEngine = AVAudioEngine()
speechRecognizer = SFSpeechRecognizer()
// 2.
SFSpeechRecognizer.requestAuthorization { authStatus in
DispatchQueue.main.async {
switch authStatus {
case .authorized:
print("Speech recognition authorized")
case .denied, .restricted, .notDetermined:
print("Speech recognition not authorized")
@unknown default:
fatalError("Unknown authorization status")
}
}
}
}
}- Initialize the
audioEngineand thespeechRecognizerproperties - Use the
requestAuthorizationmethod to request user permission to access speech recognition services. The permission result will be returned in theauthStatusparameter.
Additionally, you need to fill in the following fields in the Info.plist:
- Go into your project settings and navigate to the Info tab, as part of your project’s target;
- Add a new Key in the Custom iOS Target Properties:
Privacy - Microphone Usage Description; - Add a string value describing why the app needs access to the microphone.
- Add a new Key in the Custom iOS Target Properties:
Privacy - Speech Recognition Usage Description; - Add a string value describing why the app needs access to the speech recognition feature.
Step 3 - Accessing the microphone
After requesting all the necessary permissions we can define the method responsible for transcribing the audio received in input into text.
import Foundation
import AVFoundation
import Speech
@Observable
class SpeechRecognizer {
...
func setupSpeechRecognition() { ... }
func startListening() {
// 1.
recognitionRequest = SFSpeechAudioBufferRecognitionRequest()
recognitionRequest.shouldReportPartialResults = true
startedListening = true
// 2.
let inputNode = audioEngine.inputNode
let recordingFormat = inputNode.outputFormat(forBus: 0)
inputNode.removeTap(onBus: 0)
// 3.
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { buffer, when in
self.recognitionRequest.append(buffer)
}
// 4.
audioEngine.prepare()
try! audioEngine.start()
// 5.
speechRecognizer.recognitionTask(with: recognitionRequest) { result, error in
if let result = result {
Task {
self.recognizedText = result.bestTranscription.formattedString
}
}
if error != nil || result?.isFinal == true {
self.audioEngine.stop()
inputNode.removeTap(onBus: 0)
self.recognitionRequest = nil
self.recognitionTask = nil
}
}
}
}- Initialize the
recognitionRequestvariable and set theshouldReportPartialResultsproperty to true. In this way the recognizer will start transcribing the audio as soon it receives an input and will not wait until the entire audio is processed. - The
inputNodevariable contains the audio input received from the microphone, while therecordingFormatproperty, we retrieve the audio format for a specific bus number.
To ensure that bus 0 is empty we use the.removeTap(onBus: 0)method. - We can now define a new tap (a point where audio data is observed as it passes through the audio node) where the audio will be processed.
A copy of the audio is accessible through thebufferproperty that will added to therecognitionRequestobject using theappend()method. - Once we have the audio buffer ready to get the input we can use the
prepare()method to properly set theaudioEngineand then thestart()method to start the audio recognition. - We are now ready to start a new
recognitionTaskpassing therecognitionRequest. The closure provides the recognitionresultsand anyerrorsencountered during the process. If a result is available, it updates therecognizedTextwith the best transcription.
Step 4 - Managing microphone access
Now that we are able to process the audio from the microphone into text we can define an additional method named stopListening() that we can use to stop the recognition process.
import Foundation
import AVFoundation
import Speech
@Observable
class SpeechRecognizer {
// Properties declared in the step 1
...
func setupSpeechRecognition() {
...
}
func startListening() {
...
}
func stopListening() {
// 1.
audioEngine.stop()
audioEngine.inputNode.removeTap(onBus: 0)
// 2.
recognitionRequest.endAudio()
recognitionRequest = nil
recognitionTask = nil
startedListening = false
}
}- Using the
stop()method and removing the tap defined before we clean the audio buffer. - Using the
endAudio()method we stop any kind of request, and then restore therecognitionRequestand therecognitionTasktonil.
Step 5 - Showing the transcribed text
Now that we have our logic defined we can have fun creating a new SwiftUI View where the user can start the recognition process and visualize the processed text.
struct ContentView: View {
@State private var speechRecognizer = SpeechRecognizer()
var body: some View {
VStack(spacing: 50) {
Text(speechRecognizer.recognizedText)
.padding()
Button {
if speechRecognizer.audioEngine.isRunning {
speechRecognizer.stopListening()
} else {
speechRecognizer.startListening()
}
} label: {
Image(systemName: speechRecognizer.startedListening ? "ear.badge.waveform" : "ear")
.font(.system(size: 100))
.foregroundColor(.white)
.symbolEffect(.bounce, value: speechRecognizer.startedListening)
.symbolEffect(.variableColor, isActive: speechRecognizer.startedListening)
.background {
Circle().frame(width: 200, height: 200)
}
.padding()
}
}
.onAppear {
speechRecognizer.setupSpeechRecognition()
}
}
}- Create a new instance of the class that we defined in the previous steps.
- As soon as the view appears we call the
setupSpeechRecognition()to prompt the microphone access. - Create a button to trigger speech recognition and a
Textview to visualize the processed text.
Final Result
If you followed the previous steps you can try to run the app on your phone:
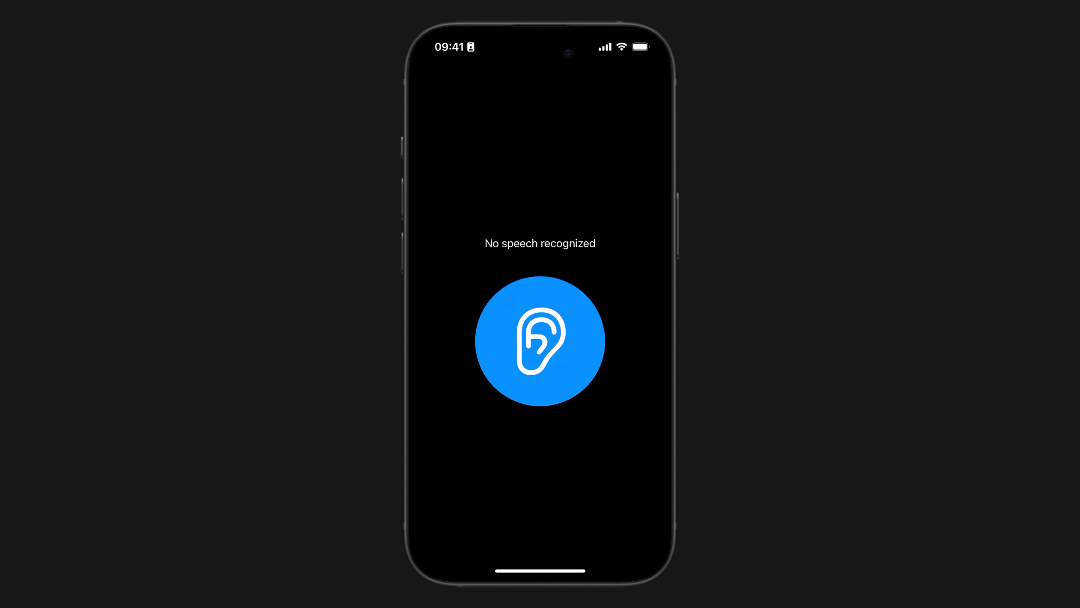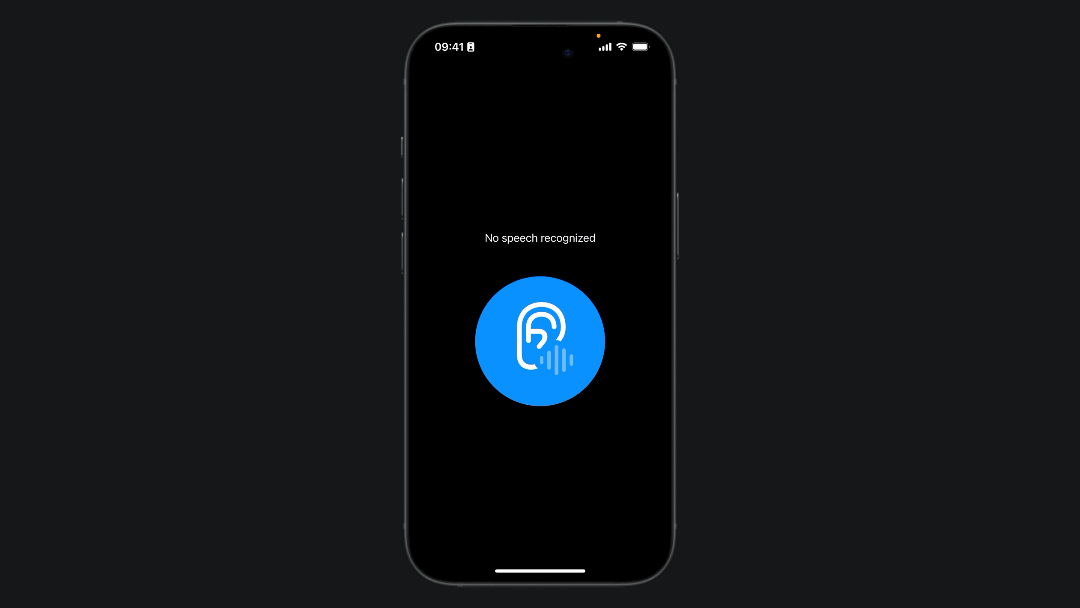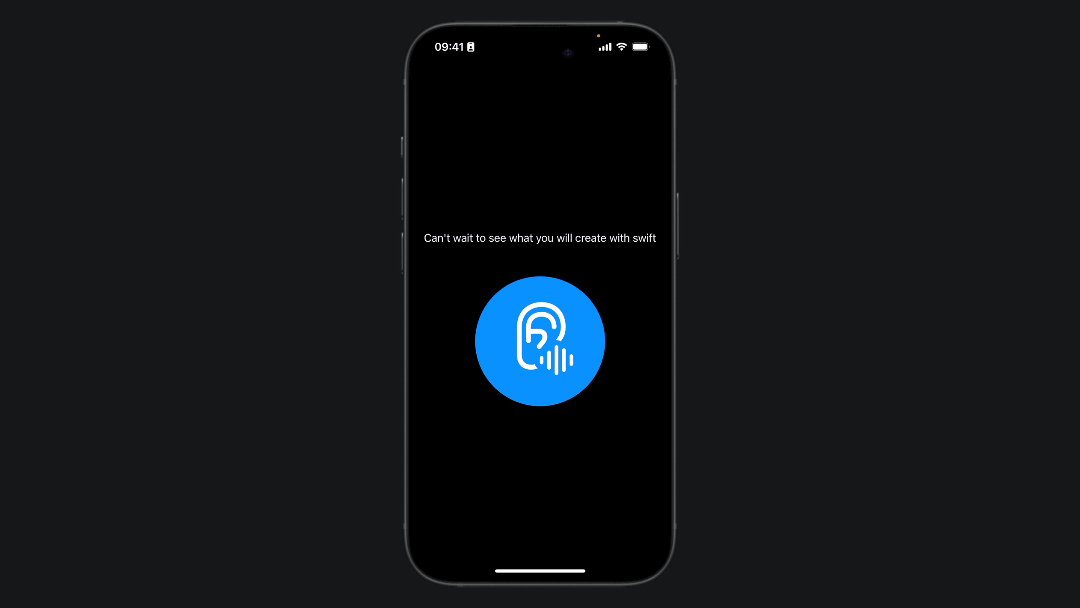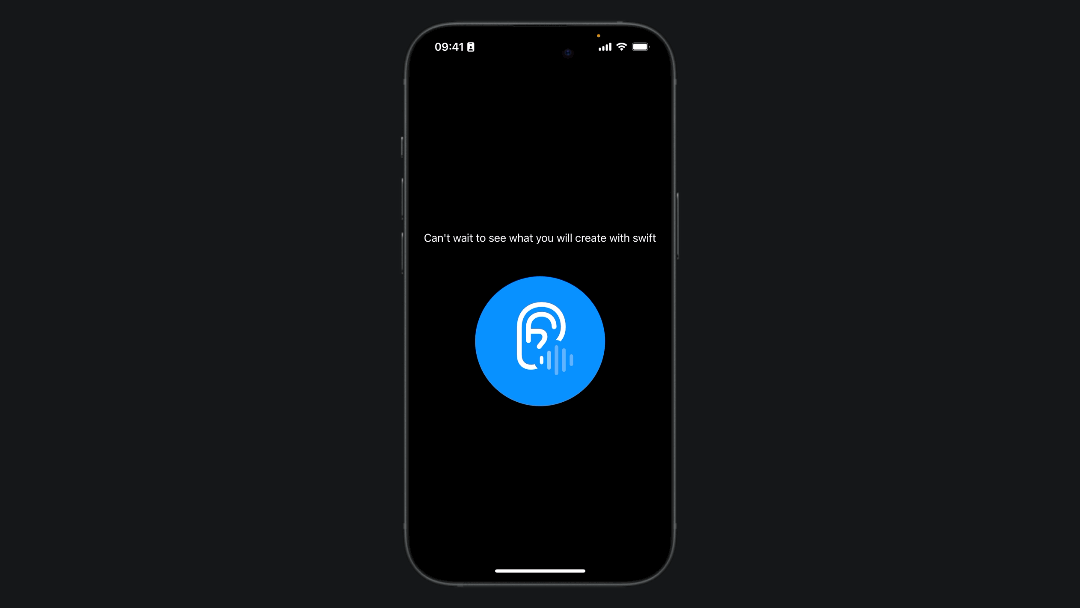
Implementing speech recognition in a SwiftUI application can significantly enhance user interaction by providing a natural and intuitive way to input data and control the app.